
Articles-First RAG: How to not Classify And Cut Chatbot Latency in Half
Articles-First RAG: How to not Classify And Cut Chatbot Latency in Half
Why Classification-First RAG Is Slower Than It Needs to Be
Open any RAG tutorial and the pattern looks the same: classify the query, route to the right knowledge base, retrieve, answer. Four stages, clean separation, easy to diagram.
The problem is stage one. Classification is typically a full LLM inference call. Before a single vector is fetched, you have already paid for a round trip to an LLM provider just to decide which bucket the question belongs to. On a content-heavy site, where 80 to 90 percent of questions are about published articles anyway, you are spending that latency to confirm what you already know most of the time.
The workflow I run started out this way. Three knowledge bases (articles, bio, legal), a classifier node up front, three routes downstream. Every question, even the obvious “what does this article say about CV rework”, ate a classification call before retrieval even began.
The core idea that reshaped the workflow: if retrieval against the articles KB succeeds with a decent similarity score, you never needed to classify in the first place. Skip the call, go straight to the index, and only fall back to classification when the articles index comes up empty.
Here is what the classification-first flow actually looked like.
Three Knowledge Bases, One Routing Strategy
The production workflow is an advanced-chat pipeline, currently at V2.2, running behind a public site. It handles three kinds of questions: questions about articles I have written, questions about me (bio, background, contact), and questions about legal pages (terms, privacy, cookies). Each lives in its own knowledge base with its own chunking and embedding config. I kept them separate because retrieval quality degrades fast when you mix a 2000-word technical article with a 40-line “About” blurb and a legal disclaimer. Mixed embeddings pull the wrong chunks for the wrong questions, and one-size-fits-all chunk sizes make every branch worse.
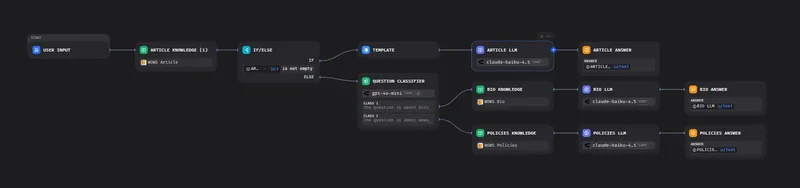
The routing strategy is the part most tutorials get backwards. Instead of starting with a question classifier that decides which knowledge base to hit, the workflow hits the articles KB first, unconditionally. Articles are where roughly 80% of real traffic lands, since that is what the chatbot is advertised to do from the article pages themselves. If the articles retrieval returns a non-empty result above the score threshold, the workflow goes straight to the answer-generation node with an articles-specific prompt. No classifier call. No router LLM. One retrieval, one generation.
Classification only runs on the miss path. If articles retrieval returns nothing usable, then the workflow invokes a question classifier node to decide between bio, legal, or a polite fallback. That classifier call is the expensive one, and now it only runs for the minority of queries that are not about articles.
The frontend is a Quarkus backend serving a SaaS landing plus an authenticated dashboard, with MinIO for asset storage, all on a small k3s cluster. The chatbot is embedded on every public article page, which is exactly why articles-first is the right default.
flowchart TD
A([User Input]) --> B[Articles KB Retrieval]
B --> C{Results Found?}
C -- TRUE --> D[Template Node Format: Title, URL, Snippet]
D --> E[Article LLM Prompt]
E --> F([Answer])
C -- FALSE --> G[Classification LLM Bio or Legal?]
G -- Bio --> H[Bio KB Retrieval]
G -- Legal --> I[Legal KB Retrieval]
H --> J[Bio LLM Prompt]
I --> K[Legal LLM Prompt]
J --> L([Answer])
K --> M([Answer])
style A fill:#4A90D9,color:#fff,stroke:none
style F fill:#27AE60,color:#fff,stroke:none
style L fill:#27AE60,color:#fff,stroke:none
style M fill:#27AE60,color:#fff,stroke:none
style C fill:#E67E22,color:#fff,stroke:none
style G fill:#8E44AD,color:#fff,stroke:none
style B fill:#2C3E50,color:#fff,stroke:#4A90D9
style D fill:#2C3E50,color:#fff,stroke:#4A90D9
style E fill:#2C3E50,color:#fff,stroke:#4A90D9
style H fill:#2C3E50,color:#fff,stroke:#8E44AD
style I fill:#2C3E50,color:#fff,stroke:#8E44AD
style J fill:#2C3E50,color:#fff,stroke:#8E44AD
style K fill:#2C3E50,color:#fff,stroke:#8E44AD
Building the Routing Logic: IF/ELSE on Retrieval Results
The workflow has four nodes on the happy path: Start → Knowledge Retrieval (articles KB) → IF/ELSE → LLM. No classifier at the top. The user query goes straight into the articles knowledge base.
The IF/ELSE node checks a single condition:
{{#knowledge_retrieval.result#}} is not empty
That is it. The platform returns an empty array when no chunk clears the score threshold (I run it at 0.5 with hybrid search, weight 0.7 semantic / 0.3 keyword). Non-empty means the articles KB had something relevant. Empty means fall back.
TRUE branch, format and answer
On the TRUE branch, a template node shapes the chunks into a structured context block before the LLM call:
{% for chunk in knowledge_retrieval.result %}
---
Title: {{ chunk.metadata.title }}
URL: {{ chunk.metadata.source_url }}
Excerpt: {{ chunk.content }}
{% endfor %}
The LLM prompt on this branch is article-specific. It tells the model: “You are answering from published articles. Always cite the article title and include the source URL in your answer. If the excerpts do not fully answer the question, say so, do not improvise.” That citation instruction only makes sense when the source is articles, which is why this prompt lives here and not upstream.
FALSE branch, classify, then retrieve again
The FALSE branch is where the classifier finally shows up, and only here. A small LLM node tags the query as bio or legal, then a second knowledge retrieval node hits the matching domain KB. A different LLM prompt handles the answer: no URL citations (domain KBs are internal reference material, not public articles), more conservative tone, explicit “consult a professional” disclaimer on the legal branch.
Why two prompts beat one
I tried a single generic prompt early on. It hedged on article questions (“you may want to verify…”) and over-cited on domain questions (inventing URLs that did not exist). Splitting the prompts by branch let each one assume its source type. The article prompt trusts its chunks and cites. The fallback prompt treats the answer as advisory. Same model, same temperature, dramatically different output quality.
Knowledge Base Setup: Chunking Strategy and Embedding Decisions
The three knowledge bases look similar in the UI but behave very differently under load. The differences are in the source, the chunk size, and the update cadence.
Articles KB source of truth is a MinIO bucket, the same bucket the Quarkus backend serves to the public site. Each article is a Markdown file with YAML frontmatter:
---
slug: articles-first-rag
title: "Articles-First RAG"
tags: [rag, dify, k3s]
published: 2024-11-03
summary: "Skipping classification to cut latency."
---
## Why classification-first hurts
Most RAG guides...
Ingestion uses chunk size 1000 tokens, overlap 100, separator \n. In my testing, blog-length content punishes small chunks: a 300-token chunk strips the surrounding argument and retrieval returns confident-looking fragments that miss the point. 1000 tokens keeps a full subsection intact. The frontmatter gets included in the first chunk, which helps when a user asks about a topic by title rather than by body keyword.
Bio KB and Legal KB are static. Bio is a few hundred words. Legal is the privacy policy and terms. Chunk size 500 tokens, overlap 50, because the content is dense and self-contained: each paragraph stands alone. Larger chunks here would dilute the embedding with unrelated clauses and hurt retrieval precision.
Embedding model is text-embedding-3-small across all three. For my corpus of technical English with code snippets and product names, it performed well enough on exact-term recall, which matters when someone asks about “k3s” or “MinIO” by name. The cost difference versus 3-large ($0.020 vs $0.130 per 1M tokens) did not justify the marginal gain at this corpus size.
Indexing pipeline treats MinIO as the source. A lightweight sync job watches the bucket via S3 event notifications, and on a new or updated object it calls the document API to re-ingest that single file. Bio and Legal are updated manually through the UI since they change maybe twice a year. No full re-index: the Articles KB would take too long and the embedding costs add up.
With the knowledge bases shaped like this, the routing logic gets simpler than you would expect.
Integrating the Chatbot with a Quarkus Backend and Kong Gateway
The chatbot does not live in isolation. The Vue 3 / Quasar frontend never talks to the chatbot API directly. Every request goes through Kong, which handles rate limiting, OIDC token validation, and routes /api/chat/* to the Quarkus backend. Quarkus then forwards to the chatbot API with a server-side key. The browser never sees that key.
Before forwarding, a budget service checks the monthly spend cap in Postgres:
@POST
@Path("/message")
@Authenticated
public Response sendMessage(ChatRequest req, @Context SecurityContext ctx) {
var tenantId = ctx.getUserPrincipal().getName();
if (!budgetService.hasRemainingBudget(tenantId)) {
return Response.status(402)
.entity(Map.of("error", "monthly_ai_budget_exceeded"))
.build();
}
var reply = chatClient.chat(req.query(), req.conversationId(), tenantId);
budgetService.recordUsage(tenantId, reply.tokenCost());
return Response.ok(reply).build();
}
Returning 402 Payment Required instead of 429 is deliberate. The frontend distinguishes “slow down” from “you hit your plan cap” and shows different UI. For more on why this matters, see the real cost of AI.
For SaaS sub-projects that need AI inside longer automations, n8n calls the same workflow through a dedicated webhook endpoint on Quarkus, not directly. That keeps budget enforcement in one place.
Redis sits behind Quarkus for two distinct jobs:
Cached blog article metadata, author info, tag lists, feature flags. TTL of one hour. These are read on every article page render.
Not cached chatbot responses. Queries vary too much, and stale answers to “what does the latest article say about X” are worse than a fresh LLM call.
OIDC session state also lives in Redis, keyed by session ID. Authenticated users get their tenant ID injected into the chatbot request as a custom variable, which the workflow uses to scope retrieval to their allowed knowledge bases. Guests hit the public articles KB only and share a single anonymous rate-limit bucket.
sequenceDiagram
participant FE as Vue 3 / Quasar Frontend
participant KG as Kong Gateway
participant QB as Quarkus Backend (BudgetService)
participant DA as Chatbot API
participant DW as Workflow Engine
participant KB as Knowledge Base
participant LLM as LLM
FE->>KG: POST /chatbot/message
KG->>QB: Forward request (auth check)
QB->>QB: Check monthly AI spend cap
alt Budget exceeded
QB-->>FE: 402 Payment Required
else Budget OK
QB->>DA: Forward to Chatbot API
DA->>DW: Trigger workflow
DW->>KB: Retrieve from Articles KB
KB-->>DW: Chunks (or empty)
alt Results found
DW->>LLM: Article LLM prompt + chunks
else No results
DW->>LLM: Classification prompt
LLM-->>DW: Bio or Legal domain
DW->>KB: Retrieve from domain KB
KB-->>DW: Domain chunks
DW->>LLM: Domain LLM prompt + chunks
end
LLM-->>DW: Generated answer
DW-->>DA: Response
DA-->>QB: Response
QB-->>KG: Response
KG-->>FE: Final answer
end
Prompt Engineering Per Domain: Why One System Prompt Is Not Enough
Once the router lands on a branch, the prompt has to match the domain. A single system prompt trying to cover articles, bio, and legal content ends up vague, and vague prompts hallucinate.
The articles branch prompt is strict about provenance. It instructs the model to cite the article title and URL from the chunk metadata, and to refuse anything not grounded in the retrieved text:
You answer questions about published articles.
Use ONLY the content in <context>. For every claim, cite the
article title and link in this format: [Title](URL).
If <context> does not contain the answer, reply exactly:
"I don't have an article covering that."
<context>
{{formatted_chunks}}
</context>
Question: {{query}}